

Is procedure more important than results?
Imagine that you need to solve the following problem. You have thousands of products from hundreds of different e-shops, and you want to predict the sales for each of them in the near future. The problem statement is quite simple, so you give it to one of your data scientists and ask him to provide you a model. Meanwhile, you ask the 3rd party company to solve the same problem and experiment with a free online tool for automatic forecasting yourself.
At the end of the month, you have three different models, all providing different results and even for a different set of products. So what now? How do you decide which model is the best?
At ShipMonk, we face a forecasting problem as described above. It is quite a typical forecasting problem – we need to predict the future for thousands of time series so we can optimize operations in our warehouses. In this article, we present how we approach the comparison of models to achieve the best and reliable results.
Metrics
First of all, and even before you approach the solution itself, you have to know how to evaluate the success of your models. There are a bunch of metrics you can use for a forecasting problem with fancy shortcuts like RMSE, MAE, FA, R2, MAPE, RMSLE, and many more. Which of these you choose highly depends on what you want to achieve with your models. So, you choose some of those metrics (or even define your own) but you must know why you have chosen those metrics and what does it mean if your model is good or bad at them.
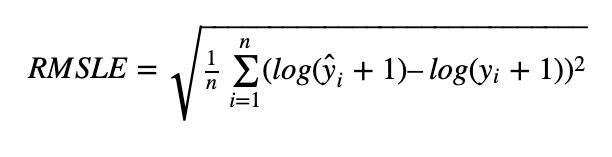
At ShipMonk we use RMSLE (Root Mean Squared Logarithmic Error) as the main metric. It behaves the same as standard MSE but in exponents of values instead of values itself. Roughly speaking we are interested in how many times we are off instead of how much. For example from the perspective of RMSLE following errors are the same, it is always wrong twice.
- The product was sold 5x and we predicted 10x
- The product was sold 50x and we predicted 100x
- The product was sold 100x and we predicted 50x
Which makes good sense in a warehouse. If we prepare twice as much inventory as needed then it stays there approximately twice as long and it does not matter if the absolute values are in dozens or thousands since there is enough space. (If there is not then we need to handle it generally, for example, decrease the time period we prepare inventory for or change the logic of inventory placement.)
However, it is really hard to get an idea of the meaning of values that RMSLE provides. That is why we sometimes use MAPE (Mean Absolute Percentage Error) when presenting results.
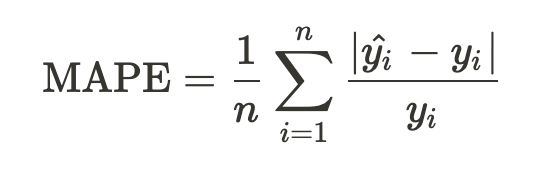
Test Dataset
So you have your metrics, and now you need to evaluate models on them. But typically you run into the issue that every model provides predictions for a slightly different set of samples. It is usually caused by the fact that various models have different requirements for input data. Let’s suppose you have just two models. How do you fairly compare them?
- You evaluate each model on all samples it predicted and compare the results. No! Those results are simply not comparable because the set of samples you predicted can be very different with a different impact.
- You evaluate models only on samples that both models predicted. Then probably the model which requires more data has better results. But the comparison is still not fair because the other model could still provide more valuable predictions in cases that are not included in the comparison.
- You impute all missing predictions with zeros for each given model and evaluate models on it. This approach is the best of three but you could disqualify a good model that is just not able to predict all the samples. We extrapolate this approach further in the following sections.
Usually, you evaluate models on an independent test dataset that no model has ever seen. In the case of forecasting where we face time series, it is important to have all samples in the test dataset strictly after any sample that the model has ever seen. There is no excuse to do it differently because in the case of production usage you cannot do it differently. The future has not happened yet.
At ShipMonk, we have special rules on how to build a test dataset. More than half of products are consistently not sold which automatically boosts the overall performance of all models. So we have a separate logic to determine which products we are interested in each day. Hence our models are evaluated only on samples we really care about.
Not Models but Methods!
To have a (fixed) test dataset is fine but as we have already mentioned some models are not able to predict all samples so its overall performance is automatically worse. But you still want to use them because they are the best at some parts of the dataset. A natural way to handle this problem is to use the “complex” model as the main model and if its prediction does not exist then fallback to some “simple” default model… And there are hundreds of other things you can do as well. In the end, you do not want to evaluate the original models anymore but the combinations you have created because that is what you are going to use in production.
At ShipMonk we distinguish between single models and methods. We generally define them as follow
- Model is a specification of learning algorithm, its hyperparameters, input and output features, et cetera. Then the trained model on a concrete train dataset, we call a model instance. Examples of models we use are Linear Regression, Neural Network, …
- Method specifies models to use, the way of training them, the way of combining their results, frequency of retraining, et cetera. It provides the whole solution of the task. It usually consists of several models where each of them could be trained differently.
Then we evaluate the results of whole methods because methods are responsible to provide results in the best way. Models themselves are usually evaluated during the development and debugging.
One Test Dataset is not Enough
Good! So you evaluate your methods on the test dataset so you have a good estimate of how they perform in production… Well, yes but you have to do it methodically right. There is a problem that time series requires to have the test dataset strictly after the training of dataset as already mentioned. The further the test dataset goes into the past the better performance estimation you have but also the further from production usage you get. You want to have a wide test dataset because it gives you better evaluation but at the same time, you want to have a short test dataset because then your model covers cases from the near past that could be very valuable for production performance. So what are you going to do? You train the chosen method again on all past data (and no test dataset) and deploy this new trained version. You just need to take care that the training was as successful as you have evaluated before.
At ShipMonk we generalize the last thought a bit. We use a long test dataset with at least one year of data. Then we run a backtest of methods on it that is as close to the production usage as possible. So if the model of the method is trained at the beginning of every month on all possible data and then it is used for the next month then the same happens in our backtest. So we do not evaluate only results themselves but the whole process of getting them, the same process we would deploy.
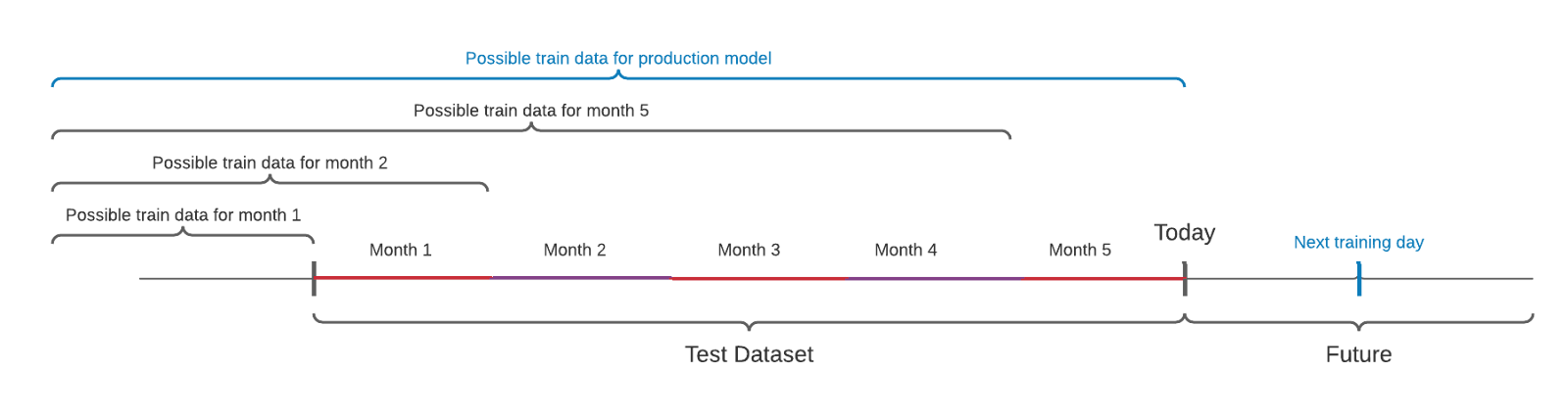
The schema of training is very similar to the time series cross-validation approach, except for the fact that every model or method can do it in its own way. One can be trained every month, another can be trained every day, and another can be universally trained just once for all time.
Let’s emphasize that the only requirement for the method is that it outputs predictions for the test dataset, and the procedure behind it can be pretty much anything. Anything while it is not cheating with the data. So our data scientists still need to be careful when developing their methods.
So, is a procedure more important than results?
Let’s go back to our original question. There is probably no general answer for this, and you have to always think about it in the context of your problem. Black-boxing vs Rule-based systems is a very discussed topic nowadays and it is very related to the question. But it would not be fair to keep the question completely unanswered so we discuss it at least from our perspective in case of the forecasting problem.
At ShipMonk we put a lot of effort into developing a general methodology to evaluate results of a high variety of methods so we eliminate the boundaries of what data scientists could do on their way to achieve the best results. Hence we have a strict procedure of how to define the test dataset and what data we can use on the way to provide results. Basically, the test dataset is always a part of the problem statement. Then we can compare any reasonable solutions against each other and we do not need to care about the approach behind them. But at the end of the day, it is always about the results you provide so the focus on the proper evaluation is a necessary step you need to take to succeed in the long run.